We, who work intensely in the BI space know (and often struggle to properly explain), that it’s about understanding results a.k.a. data storytelling – where it came from, how was it processed, and what insights it gives us. This level is only possible if we know the Data Flow which is the largest source of value.
Data Flow
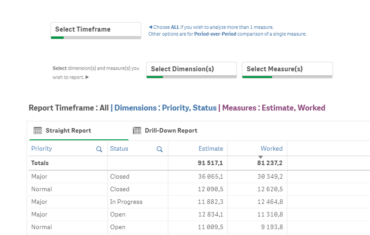
Take for example our calculation of net revenues (see video with dummy data) – it takes six steps to calculate it, and the partial result in each can be radically different. We consolidate intercompany, join costs, clean, and categorize source data, which needs to be up-to-date and accessed by an account with sufficient rights. Understanding this flow by everyone, who takes an interest in these values, builds trust in data which encourages usage.
A further benefit is that this is the safest way to minimize data disputes. You know, those are the situations when people argue about whose number is correct at a meeting – wasted time for everyone who attends. So, this data transparency also helps to keep leaders aligned.
Understanding the flow means I can improve the process because today’s business processes are data. For example, if the sales rep. enters the wrong category in the CRM, I will get the wrong result. By analysing the results back to the source I might come up with safeguards and automation that will make the whole process work better for everyone – increase the quality of our interactions with colleagues, customers, suppliers, or partners.
The possibility to review end-to-end data flow is another BI capability that could use more innovation. It will allow people to extract more value from data (not just results), converting more of it into an asset.
Data Associativity
Every GB of data we produce and store costs something and ideally, we would like to create more than just one-time value out of it – make it an asset. Since we produce more data, the pressure on BI to innovate is high.
A lot has changed since I worked on my first data analytics project 16 years ago, mainly about performance and user experience. When I think about trends and innovation, I like to stay away from overhyped topics and focus more on principles.
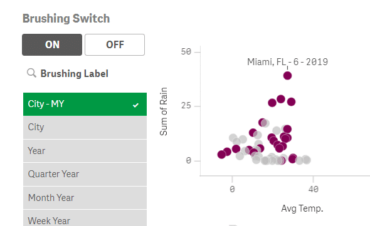
The first principle/challenge that I see for BI innovation is better data associativity. I mean the capability to associate (or join/merge) two or more datasets, regardless of the format (numbers, dates, strings…) or scale (hundreds or billions of rows). Sounds simple but resolving inconsistencies can stall a project for days or weeks on one dataset when you need to resolve tens or hundreds.
Any dataset becomes much more valuable if it can be associated with another. For example, one of the mega-generators of data will be IoT. Just one sensor sending data every minute will give us about half a million records per year. Now think about a thousand sensors sending data every second. If we know a reference (limit or benchmark) then we need only the current value, maybe the last day to spot a trend. So, we could disregard 99+% of this data as irrelevant. That will dramatically change when we associate it with e.g. service data, and I don’t mean a reductive join. A true association will keep all values in both datasets and reveal existing as well as non-existing relationships. And that grey area is often the most interesting.
Data associativity is key if we want to even think of advanced analytics, predictions, data mining, or data sharing with business partners. When BI will assist us with associating datasets better, then we’ll be able to forecast business and mitigate risk faster.
What the Future Holds.
I ran across a statistic on the volume of data which is measured in zettabytes. That is one billion terabytes or about one trillion gigabytes. The total number is of course very virtual for most of us, but the observed trend is very real and predicts that by 2025 the volume of data will double.
What will drive this increase? From what I read/heard:
- people = we want data, about everything; I’ve noticed a sort of general awareness that data make you more informed and bring you comfort;
- companies want to (semi)automize most of their processes, thus creating not only transactional data but also a lot of logs on usage, system status, and events;
- customers, suppliers, and other business partners expect us to share relevant data with them to streamline processes (and not only when we send them invoices);
- massive data-generating technologies are being widely adopted > IoT, 5G, IPV6, Web3, and even the infamous blockchain;
- more and faster data means higher vulnerability, thus increasing the need to create more data about data = metadata.
So, what’s the challenge? Well, I guess generating every GB costs something, and ideally, we’d like it to create more than one-time value = making it an asset. However, most of the produced data is not retained or just forgotten, and only a smaller part of the remaining is used for data analytics. This increases pressure on innovation in BI because, without it, the data value gap will only get wider.