
Korelácia neimplikuje kauzalitu – túto vetu ste už pravdepodobne počuli. Skôr než sa však rozhodnete, či kauzalita existuje alebo nie, mali by ste poznať skutočnú koreláciu a ideálne aj vedieť, či je korelácia štatisticky významná. Nechápte ma zle: ani štatisticky významná korelácia neimplikuje kauzalitu, ale aspoň viete, že silná pozitívna alebo negatívna korelácia nie je len výsledkom náhody. Dnes sa naučíme, ako môžeme vypočítať hodnoty korelácie spolu s ich P-hodnotami. Vizualizovať budeme iba tie významné pomocou korelačnej matice v Qlik Sense integrovanej s R.
Čo je korelácia
Korelácia je číslo medzi -1 a 1, ktoré vám hovorí, aký silný je lineárny vzťah medzi dvoma premennými. Hodnoty blízke -1 znamenajú, že medzi dvoma premennými existuje negatívny lineárny vzťah. Hodnoty blízke 1 znamenajú silný pozitívny vzťah medzi dvoma premennými. Ak sa korelačný koeficient nachádza blízko 0, medzi dvoma premennými neexistuje lineárny vzťah. Existuje mnoho prípadov, keď je korelačný koeficient blízko 0, ale medzi premennými existuje silná závislosť, len nie lineárna (napríklad kvadratický vzťah môže byť korelačným koeficientom prehliadnutý). Bežne používaný korelačný koeficient sa nazýva Pearsonov korelačný koeficient.
Načítanie dát do Qlik Sense
Stiahnite si dáta tu. Dataset obsahuje údaje z 1985 Ward’s Automotive Yearbook. Najskôr by sme mali premenovať stĺpce pomocou aliasov v Qlik Sense, pretože R nemá rád znak ‚-‚ v názvoch stĺpcov a nahradil by ho bodkou ‚.‘, čo by vytvorilo zbytočný chaos.
Načítanie dát
CarData: LOAD RowNo() as "car_ID", symboling, "normalized-losses" as "normalizedlosses", make, "fuel-type" as "fueltype", aspiration, "num-of-doors" as "numofdoors", "body-style" as "bodystyle", "drive-wheels" as "drivewheels", "engine-location" as "enginelocation", "wheel-base" as "wheelbase", "length", width, height, "curb-weight" as "curbweight", "engine-type" as "enginetype", "num-of-cylinders" as "numofcylinders", "engine-size" as "enginesize", "fuel-system" as fuelsystem, bore, stroke, "compression-ratio" as "compressionratio", horsepower, "peak-rpm" as "peakrpm", "city-mpg" as "citympg", "highway-mpg" as "highwaympg", price FROM [lib://Data/Correlation matrix/Automobile_data.csv] (txt, codepage is 28591, embedded labels, delimiter is ';', msq);
Spustenie R skriptu
Teraz musíme pomocou R vypočítať korelácie a príslušné P-hodnoty. Neváhajte použiť nasledujúci skript.
Tmp_Correlation: Load * Extension R.ScriptEval( '# install.packages(Hmisc, repos="http://cran.us.r-project.org"); //ponechajte # ak už máte tento balík nainštalovaný library(Hmisc); df <- as.data.frame.list(q, strings.as.factors = FALSE); df <- Filter(is.numeric, df); cor <- as.data.frame.list(rcorr(as.matrix(df), type="pearson")); cor$varname <- rownames(cor); cor;', CarData{wheelbase,length,width,height,curbweight,enginesize,bore,stroke,compressionratio,horsepower,peakrpm,citympg,highwaympg,price});
Transformácia výsledku z R skriptu
R skript vracia kompaktnú tabuľku obsahujúcu všetko. Preferujem ju trochu vyčistiť, aby sme skončili s pekným dátovým modelom.
Tmp_Correlation_Crosstable: CROSSTABLE (Variable2, Value) LOAD varname as Variable1, * RESIDENT Tmp_Correlation ; Tab_Correlation: LOAD , Variable1&'|'&Variable2 as %KeyCor; LOAD Variable1, Replace(Variable2, 'r.', '') as Variable2, Value as Correlation RESIDENT Tmp_Correlation_Crosstable Where Variable2 like 'r.'; Tab_PValues: LOAD [P-Value], Variable1&'|'&Variable2 as %KeyCor; LOAD Variable1, Replace(Variable2, 'P.', '') as Variable2, Value as [P-Value] RESIDENT Tmp_Correlation_Crosstable Where Variable2 like 'P.*'; Drop Tables Tmp_Correlation, Tmp_Correlation_Crosstable;
Mali by ste skončiť s dvojtabuľkovým dátovým modelom, ktorý vyzerá takto:

Vytvorenie korelačnej matice v Qlik Sense
Výborná práca! Sme pripravení nastaviť vizualizáciu nad dátovým modelom, ktorý máme. Výsledkom bude korelačná matica zobrazujúca aktuálne hodnoty Pearsonovho korelačného koeficientu spolu s farbami (tmavomodrá pre negatívne korelácie a červená pre pozitívne). Okrem toho budeme mať aj slider na výber úrovní P-hodnôt, ktoré sa budú zobrazovať. Týmto spôsobom môžete zobrazovať a analyzovať iba štatisticky významné korelácie a zároveň si vybrať ľubovoľnú úroveň významnosti.
Vytvorenie korelačnej matice pomocou heatmap grafu
Vyberte Heatmap chart z Qlik Visualization bundle a nastavte:
- Data > Dimensions: nastavte 2 dimenzie Variable1 a Variable2
- Vytvorte novú premennú vSign a ponechajte Definition prázdne
- Data > Measures:
=Avg({<[P-Value] = {"<=$(vSign)"}>} Correlation); nastavte label na Pearsonov korelačný koeficient - Appearance > Options: Nepoužívajte mean in scale a namiesto toho použite fixed scale. Nastavte Min Scale Value na -1; Max Scale Value na 1 a Minimum Horizontal Size na 0
- Appearance > Design: Vyberte farebnú schému Qlik Sense Diverging
- Appearance > General: nastavte názov na Korelačná matica
Spravte heatmap responzívnu na úroveň významnosti
Heatmap je nastavený, ale stále musíme pridať nejaký vstup na priradenie hodnôt do premennej vSign. Použime na to slider.
Choďte do Custom objects > Qlik Dashboard bundle > Variable input. Zmeňte ho na slider a priraďte tejto vizualizácii premennú vSign. Nastavte Min na 0.01 a Max na 1. Krok by mal byť nastavený na 0.01. Hotovo, máte plne interaktívnu korelačnú maticu s možnosťou výberu úrovne štatistickej významnosti. Posúvajte slider a sledujte, ako nevýznamné korelácie miznú.
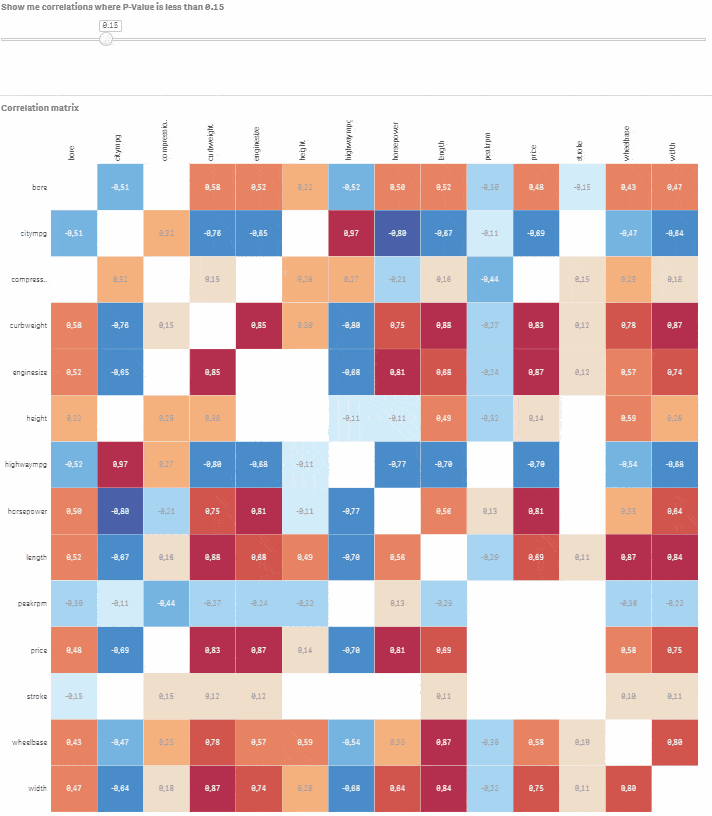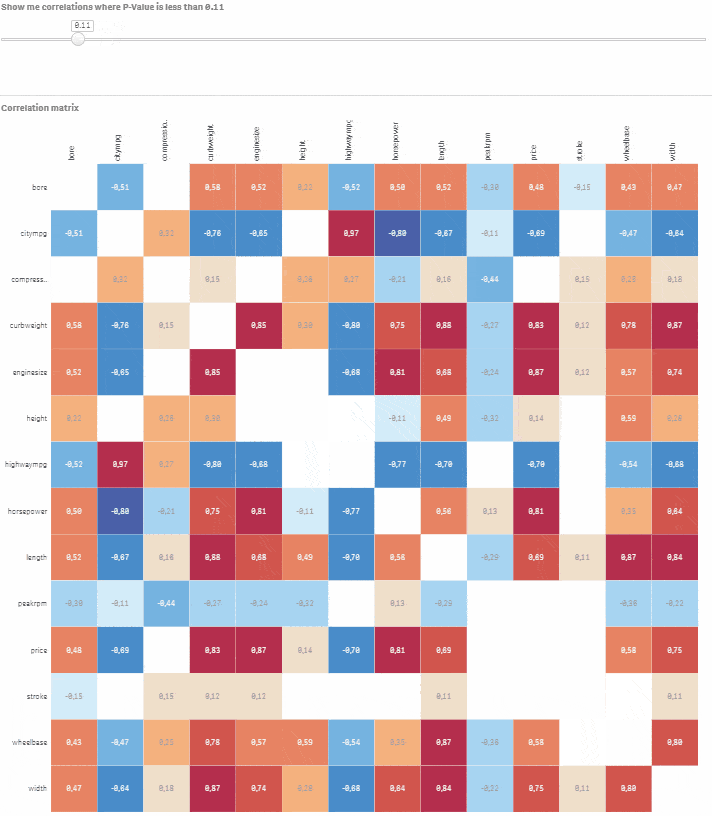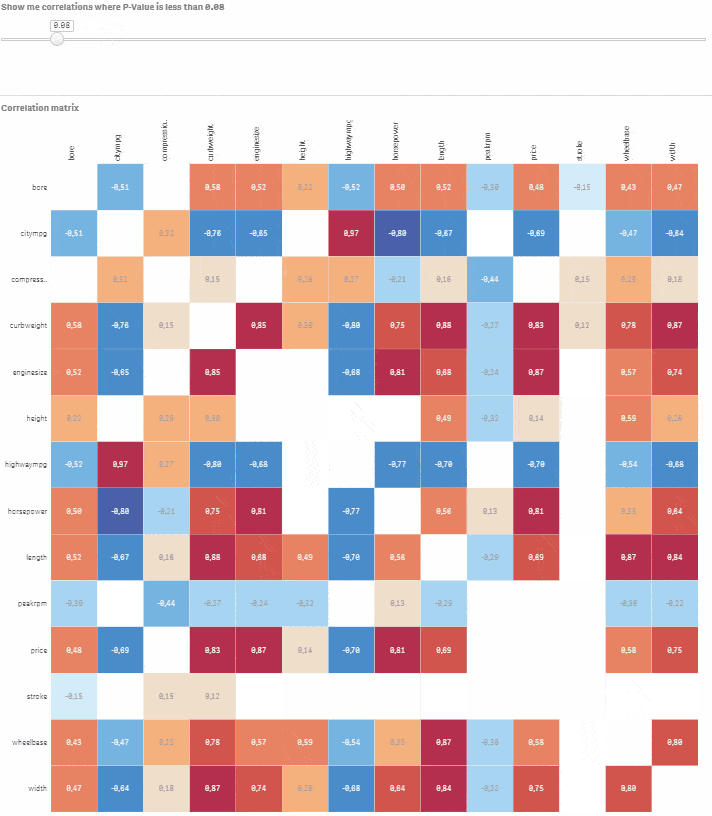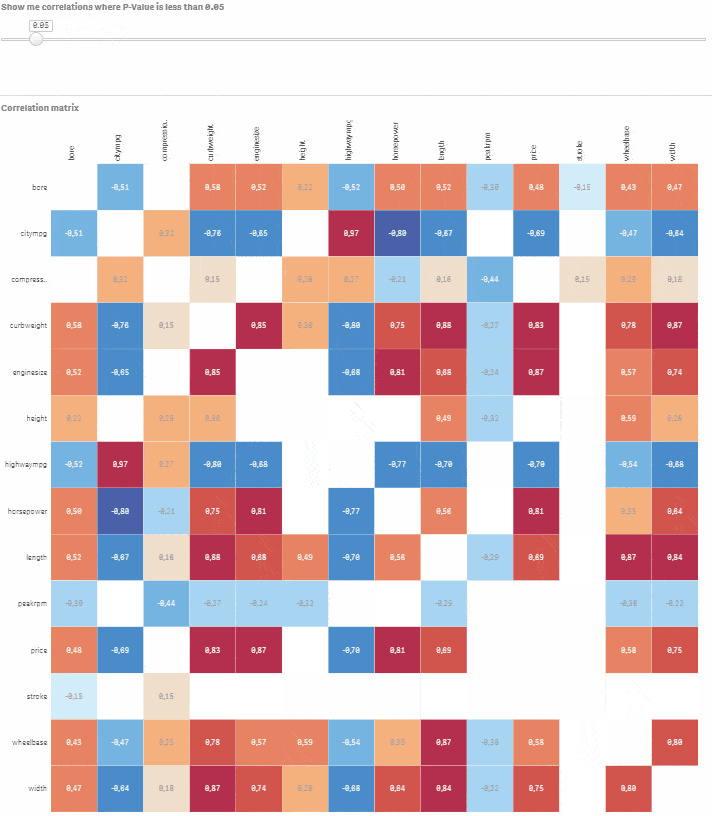
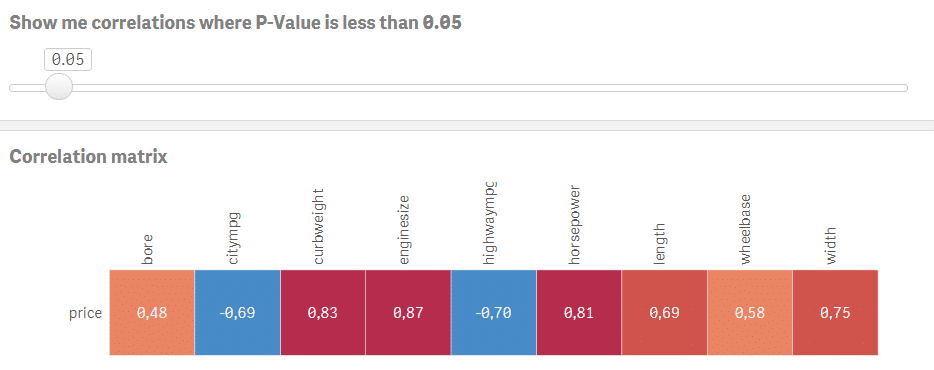
Povedzme, že chcete modelovať cenu auta na základe ostatných numerických premenných. Kliknite na príslušný riadok a pomocou slidera vyberte korelácie, kde je P-hodnota menšia alebo rovná 0.05. Teraz máte dobrý východiskový bod pre vytvorenie modelu s cenou ako závislou premennou a bore, citympg, curbweight, enginesize, highwaympg, length, wheelbase, width ako vysvetľujúcimi premennými.
Ak vás to zaujíma, pokračujte a pozrite si posledný článok zo série Kreatívne vizualizácie v Qlik Sense o Q-Q grafe.


