
Correlation does not imply causation – to jste už pravděpodobně slyšeli. Než se však rozhodnete, zda kauzalita existuje nebo ne, měli byste znát skutečnou korelaci a ideálně také vědět, zda je korelace statisticky významná. Nechápejte mě špatně: ani statisticky významná korelace neimplikuje kauzalitu, ale alespoň víte, že silná pozitivní nebo negativní korelace není pouze výsledkem náhody. Dnes se naučíme, jak můžeme vypočítat hodnoty korelace spolu s jejich P-hodnotami. Vizualizovat budeme pouze ty významné pomocí korelační matice v Qlik Sense integrované s R.
Co je korelace
Korelace je číslo mezi -1 a 1, které vám říká, jak silný je lineární vztah mezi dvěma proměnnými. Hodnoty blízké -1 znamenají, že mezi dvěma proměnnými existuje negativní lineární vztah. Hodnoty blízké 1 znamenají silný pozitivní vztah mezi dvěma proměnnými. Pokud se korelační koeficient nachází blízko 0, mezi dvěma proměnnými neexistuje lineární vztah. Existuje mnoho případů, kdy je korelační koeficient blízko 0, ale mezi proměnnými existuje silná závislost, jen ne lineární (například kvadratický vztah může být korelačním koeficientem přehlédnut). Běžně používaný korelační koeficient se nazývá Pearsonův korelační koeficient.
Načtení dat do Qlik Sense
Stáhněte si data zde. Dataset obsahuje údaje z 1985 Ward’s Automotive Yearbook. Nejprve bychom měli přejmenovat sloupce pomocí aliasů v Qlik Sense, protože R nemá rád znak ‚-‚ v názvech sloupců a nahradil by jej tečkou ‚.‘, což by vytvořilo zbytečný chaos.
Načtení dat
CarData: LOAD RowNo() as "car_ID", symboling, "normalized-losses" as "normalizedlosses", make, "fuel-type" as "fueltype", aspiration, "num-of-doors" as "numofdoors", "body-style" as "bodystyle", "drive-wheels" as "drivewheels", "engine-location" as "enginelocation", "wheel-base" as "wheelbase", "length", width, height, "curb-weight" as "curbweight", "engine-type" as "enginetype", "num-of-cylinders" as "numofcylinders", "engine-size" as "enginesize", "fuel-system" as fuelsystem, bore, stroke, "compression-ratio" as "compressionratio", horsepower, "peak-rpm" as "peakrpm", "city-mpg" as "citympg", "highway-mpg" as "highwaympg", price FROM [lib://Data/Correlation matrix/Automobile_data.csv] (txt, codepage is 28591, embedded labels, delimiter is ';', msq);
Spuštění R skriptu
Nyní musíme pomocí R vypočítat korelace a příslušné P-hodnoty. Neváhejte použít následující skript.
Tmp_Correlation: Load * Extension R.ScriptEval( '# install.packages(Hmisc, repos="http://cran.us.r-project.org"); //ponechte # pokud už máte tento balíček nainstalovaný library(Hmisc); df <- as.data.frame.list(q, strings.as.factors = FALSE); df <- Filter(is.numeric, df); cor <- as.data.frame.list(rcorr(as.matrix(df), type="pearson")); cor$varname <- rownames(cor); cor;', CarData{wheelbase,length,width,height,curbweight,enginesize,bore,stroke,compressionratio,horsepower,peakrpm,citympg,highwaympg,price});
Transformace výsledku z R skriptu
R skript vrací kompaktní tabulku obsahující vše. Preferuji ji trochu vyčistit, abychom skončili s pěkným datovým modelem.
Tmp_Correlation_Crosstable: CROSSTABLE (Variable2, Value) LOAD varname as Variable1, * RESIDENT Tmp_Correlation ; Tab_Correlation: LOAD , Variable1&'|'&Variable2 as %KeyCor; LOAD Variable1, Replace(Variable2, 'r.', '') as Variable2, Value as Correlation RESIDENT Tmp_Correlation_Crosstable Where Variable2 like 'r.'; Tab_PValues: LOAD [P-Value], Variable1&'|'&Variable2 as %KeyCor; LOAD Variable1, Replace(Variable2, 'P.', '') as Variable2, Value as [P-Value] RESIDENT Tmp_Correlation_Crosstable Where Variable2 like 'P.*'; Drop Tables Tmp_Correlation, Tmp_Correlation_Crosstable;
Měli byste skončit s dvoutabulkovým datovým modelem, který vypadá takto:

Vytvoření korelační matice v Qlik Sense
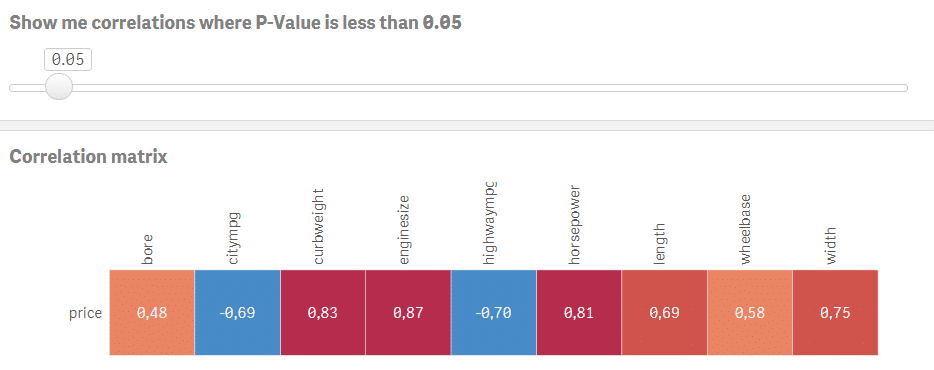
Výborná práce! Jsme připraveni nastavit vizualizaci nad datovým modelem, který máme. Výsledkem bude korelační matice zobrazující aktuální hodnoty Pearsonova korelačního koeficientu spolu s barvami (tmavě modrá pro negativní korelace a červená pro pozitivní). Kromě toho budeme mít také slider pro výběr úrovní P-hodnot, které se budou zobrazovat. Tímto způsobem můžete zobrazovat a analyzovat pouze statisticky významné korelace a zároveň si vybrat libovolnou úroveň významnosti.
Vytvoření korelační matice pomocí heatmap grafu
Vyberte Heatmap chart z Qlik Visualization bundle a nastavte:
- Data > Dimensions: nastavte 2 dimenze Variable1 a Variable2
- Vytvořte novou proměnnou vSign a ponechte Definition prázdné
- Data > Measures:
=Avg({<[P-Value] = {"<=$(vSign)"}>} Correlation); nastavte label na Pearsonův korelační koeficient - Appearance > Options: Nepoužívejte mean in scale a místo toho použijte fixed scale. Nastavte Min Scale Value na -1; Max Scale Value na 1 a Minimum Horizontal Size na 0
- Appearance > Design: Vyberte barevné schéma Qlik Sense Diverging
- Appearance > General: nastavte název na Korelační matice
Udělejte heatmap responzivní na úroveň významnosti
Heatmap je nastaven, ale stále musíme přidat nějaký vstup pro přiřazení hodnot do proměnné vSign. Použijme k tomu slider.
Přejděte do Custom objects > Qlik Dashboard bundle > Variable input. Změňte jej na slider a přiřaďte této vizualizaci proměnnou vSign. Nastavte Min na 0.01 a Max na 1. Krok by měl být nastaven na 0.01. Hotovo, máte plně interaktivní korelační matici s možností výběru úrovně statistické významnosti. Posouvejte slider a sledujte, jak nevýznamné korelace mizí.
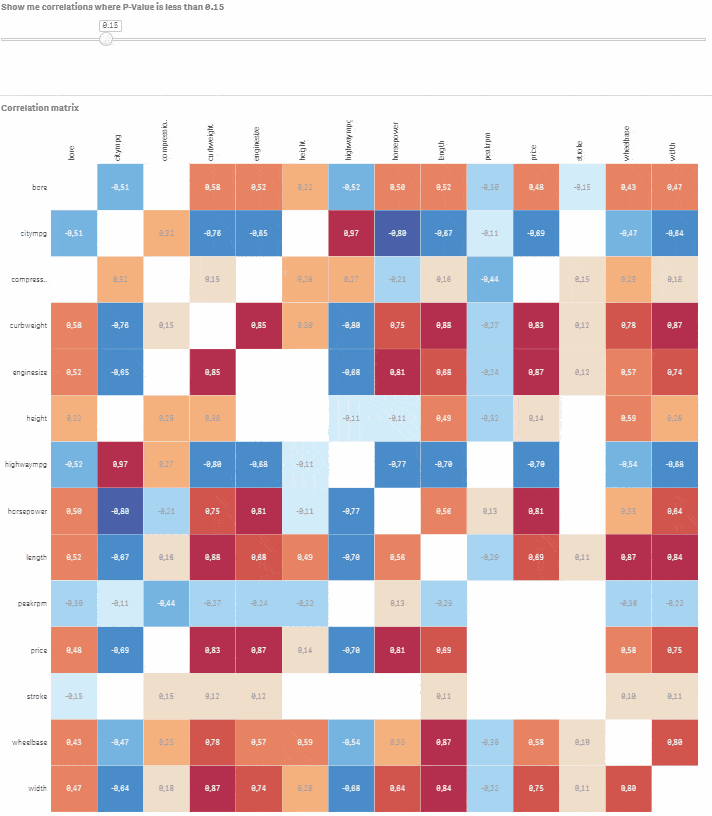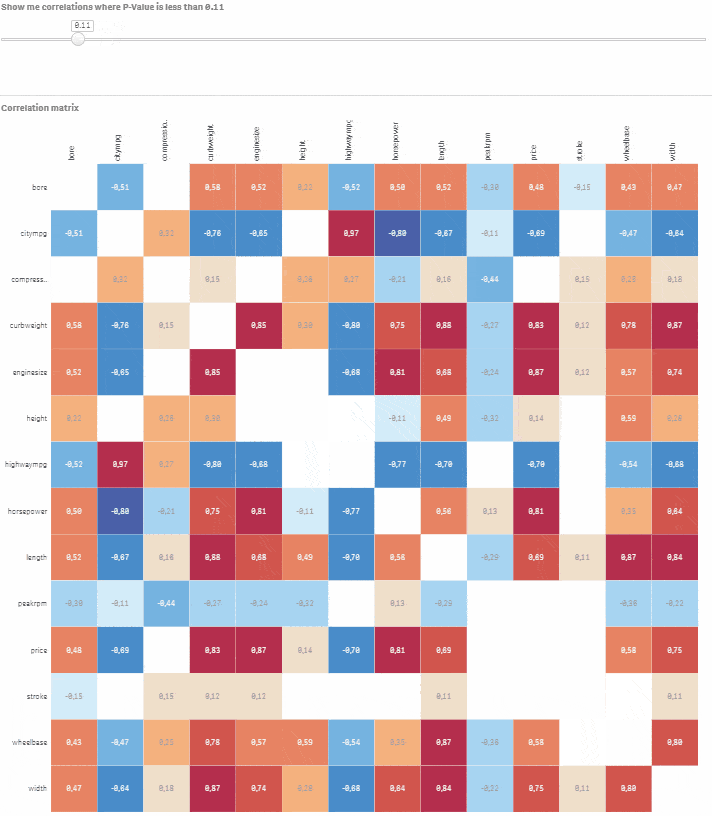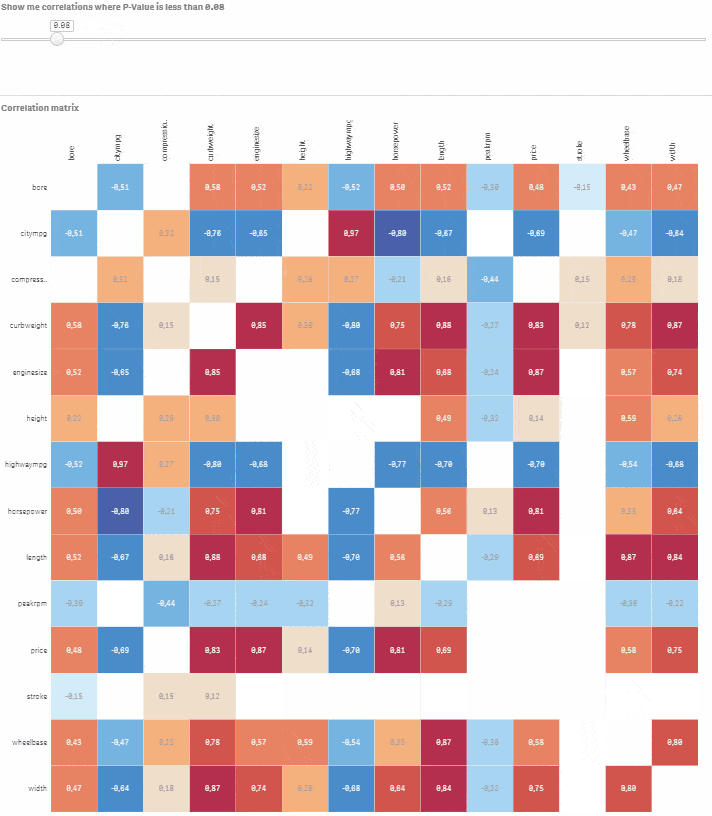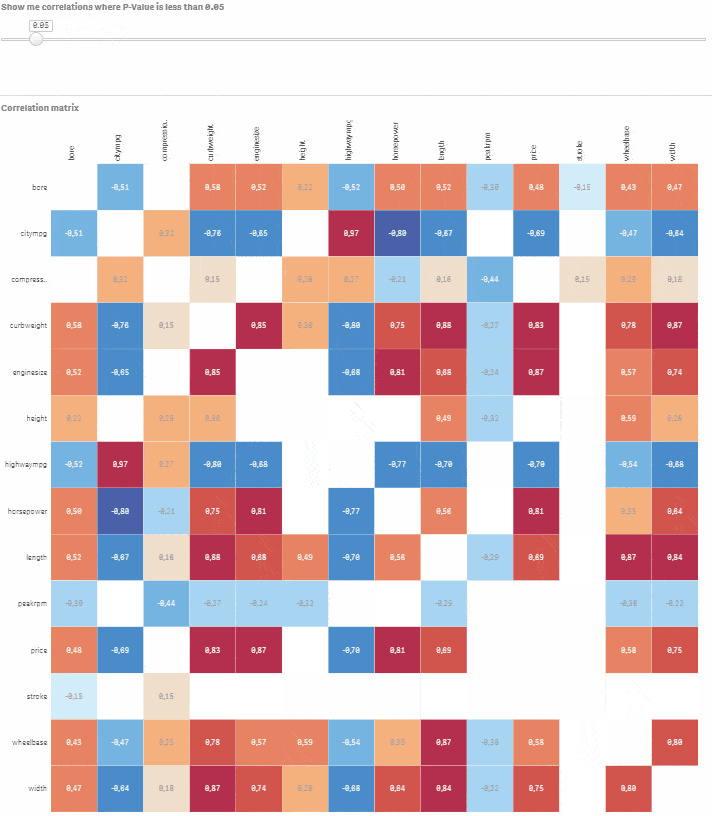
Řekněme, že chcete modelovat cenu auta na základě ostatních numerických proměnných. Klikněte na příslušný řádek a pomocí slideru vyberte korelace, kde je P-hodnota menší nebo rovna 0.05. Nyní máte dobrý výchozí bod pro vytvoření modelu s cenou jako závislou proměnnou a bore, citympg, curbweight, enginesize, highwaympg, length, wheelbase, width jako vysvětlujícími proměnnými.
Pokud vás to zajímá, pokračujte a podívejte se na poslední článek ze série Kreativní vizualizace v Qlik Sense o Q-Q grafu.


