
Existuje mnoho prípadov použitia, ktoré vyžadujú určitý typ porovnania. Môžete byť požiadaní o porovnanie obchodníkov, oddelení, krajín, technológií alebo dokonca druhov kvetov. Dnes budeme používať známy dataset kvetov Iris. Na jednej strane sa cítim trochu previnilo za nedostatok kreativity pri výbere datasetu, na druhej strane je dataset jednoduchý na stiahnutie, ľahko pochopiteľný a poskytuje pekne vyzerajúci hustotný graf. Dáta si stiahnite tu. CSV obsahuje 50 vzoriek 3 rôznych druhov kosatcov a atribúty: dĺžka kališného lístka, šírka kališného lístka, dĺžka okvetného lístka a šírka okvetného lístka v cm. Načítajte dáta do Qlik Sense tak, aby bol v dátovom modeli 1 stôl, nie sú potrebné žiadne transformácie. Pomenujte tabuľku IrisData.
Ukážte mi čísla
Budeme porovnávať dĺžku kališného lístka troch rôznych druhov. Prvá vec, ktorá mi napadne, je vypočítať priemer pre každý typ kosatca. Niekto by mohol namietať, že medián je lepšia voľba a pravdepodobne by mal pravdu. Ak chceme nájsť stred dát, medián je zvyčajne lepšia voľba. Urobme oboje: 
Teraz vieme, že najdlhšie kališné lístky patria versicolor, ale čo ak sa dĺžky výrazne líšia v rámci jednej kategórie kosatcov? Čím väčší je rozptyl, tým menej významné sú rozdiely v priemeroch. Veľmi známou mierou rozptylu je štandardná odchýlka:
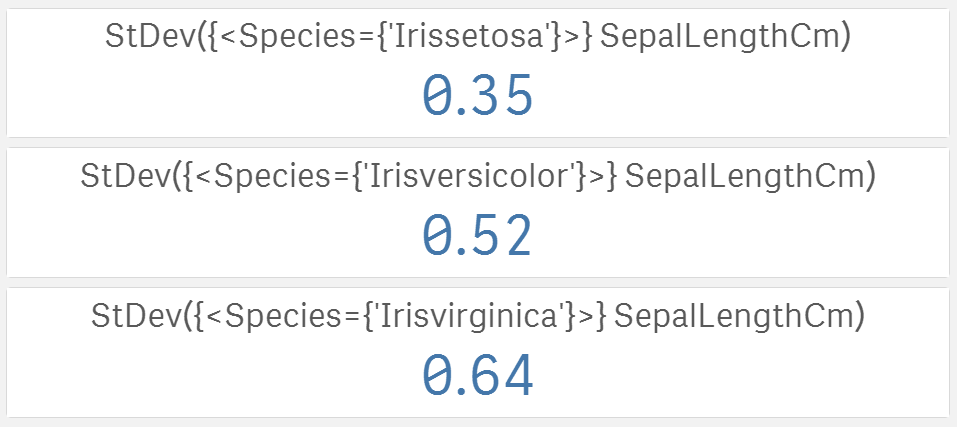
Teraz vieme, že setosa má oveľa menší rozptyl než virginica. Poslednou chýbajúcou informáciou je tvar dát.
Vizualizujte rozdiely
Sú dĺžky asymetrické alebo symetrické? Možno je jedno rozdelenie špicatejšie než ostatné (mohli by sme tiež vypočítať špicatosť, aby sme to zistili). Histogram by nám to mohol povedať, ale nie som najväčším fanúšikom histogramu v Qlik Sense. Nechápte ma zle. Qlik je skvelý BI nástroj, ale jednoducho nie je navrhnutý ako štatistický nástroj. Najviac mi chýbajú nastavenia minimálnych/maximálnych hodnôt na osi x (nedostupné vo verzii November 2019 a starších), ktoré by boli veľmi užitočné na porovnanie tvaru, stredov, asymetrie a špicatosti. Ale zatiaľ pracujme s tým, čo máme:

Neviem ako vy, ale tieto histogramy nám priniesli len málo informácií v porovnaní s potenciálom tohto grafu. Áno, existujú rozdiely v tvaroch, ale aké veľké sú tieto rozdiely? Kvôli nedostatku nastavení min/max osi x nám chýbajú informácie o rozdieloch v stredoch dát a rozdieloch v rozptyle. Napríklad už zo štandardných odchýlok vieme, že setosa má najmenší rozptyl, ale vidíte to tu? Ak sa nepozeráte na hodnoty osi x, mohli by ste ľahko predpokladať, že rozptyl všetkých troch je rovnaký, a to by bolo ďaleko od reality. Budeme musieť ísť trochu hlbšie.
Existujú 2 pekné vizualizácie v Qlik Sense zobrazujúce, kde sa dáta nachádzajú a aký veľký je rozptyl v jednom obrázku – distribučný graf vľavo a box plot vpravo. Ak ste majstrom box plotov, môžete tam trochu vidieť aj tvar.

Toto mi nestačí. Musí existovať lepší spôsob, ako vidieť všetko pekne v jednom jednoduchom obrázku. Poďme si pomôcť pomocou R a vytvorme hustotný graf v Qlik Sense.
Použite R na získanie dát hustotného grafu
Použijeme R na výpočet hodnôt hustoty. Ak sa chcete dozvedieť viac o hustotnej funkcii a ako funguje, pozrite sa sem. Existujú 2 spôsoby, ako používať R a Qlik Sense spolu. Buď ich ponecháte oddelené a načítate výsledky z R do Qlik Sense ako akýkoľvek iný zdroj dát, alebo použijete SSE R-plugin na odoslanie dát, spustenie R skriptu a prijatie dát priamo v Qlik Sense bez potreby externého uloženia výsledkov. Nasledujúce riadky môžete použiť, ak máte Qlik Sense integrovaný s R cez plugin. S trochou znalostí R je možné skript jednoducho upraviť tak, aby bežal v R mimo Qlik Sense.
IrisDataDensity: Load * Extension R.ScriptEval( '# install.packages(tidyverse, repos="http://cran.us.r-project.org"); //ponechajte # ak už máte tento balík nainštalovaný # install.packages(magrittr, repos="http://cran.us.r-project.org"); //ponechajte # ak už máte tento balík nainštalovaný library(tidyverse); library(magrittr); data <- as.data.frame.list(q); data %<>% pivot_wider(names_from = "Species", values_from = "SepalLengthCm") %>% apply(2, density, na.rm=TRUE) %>% unlist(recursive=FALSE);
result <- as.data.frame( data[endsWith(names(data), ".x")|endsWith(names(data), ".y")]);
result %<>% mutate(DensID = row_number()) %>% select(DensID, everything()) %>% select(-c("Id.x", "Id.y")) %>% pivot_longer(cols = -"DensID") %>% separate(col = name, into = c("Iris", "Species", "Coordinate")) %>% mutate(Species = paste(Iris, Species, sep = "-")) %>% select(-Iris) %>% pivot_wider(names_from = "Coordinate", values_from = "value");',
IrisData{Id, SepalLengthCm, Species});
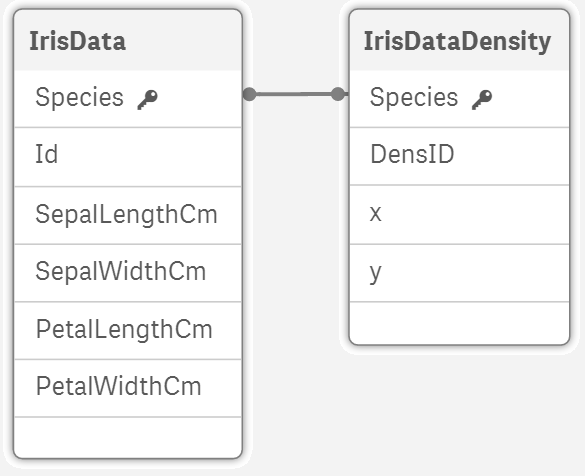
Skript pridá novú tabuľku do nášho dátového modelu:
Vytvorte hustotný graf
Ako základ použijeme štandardný čiarový graf. Nastavte nasledovné:
- x ako Group Dimension
- Species ako Line Dimension
- y ako Measure
- prepnite čiarový graf na plošný graf v sekcii presentation
- v nastaveniach osi x zaškrtnite možnosť Use continuous scale
- nastavte popisy a názov
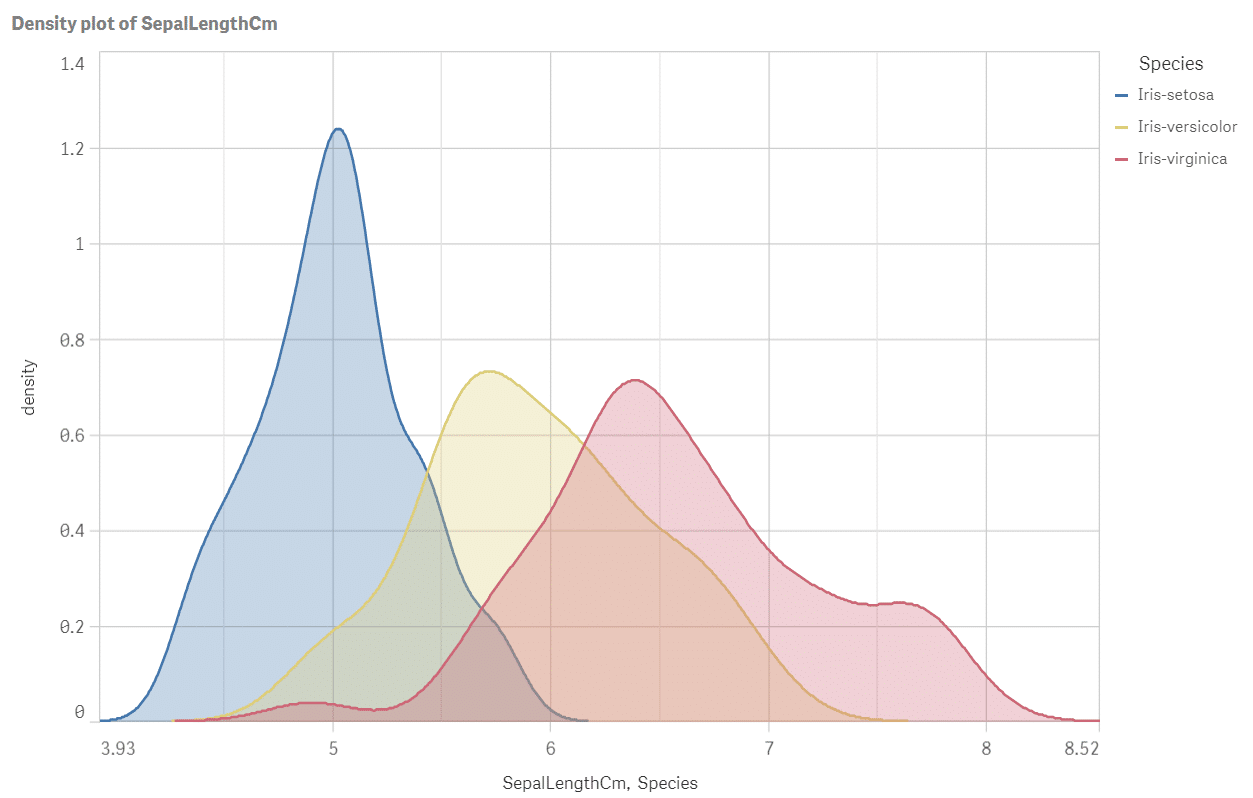
Perfektné! Máme všetky odpovede v jednom obrázku: ako sa druhy líšia z hľadiska polohy, rozptylu a tvaru dát dĺžky kališného lístka? Najdlhšie kališné lístky sú typické pre virginica a najmenšie pre setosa. Pozrite sa na šírky grafov: rozptyl virginica je približne dvakrát väčší ako rozptyl setosa. Versicolor sa zdá byť mierne asymetrický a rozdelenie setosa je špicatejšie. Spustite skript aj pre ďalšie atribúty kosatcov alebo ešte lepšie: optimalizujte a rozšírte ho tak, aby počítal hustotu pre všetky miery SepalLengthCM, SepalWidthCm, PetalLengthCm a PetalWidthCm naraz.
Pozrite si aj posledný článok zo série Kreatívne vizualizácie v Qlik Sense o animovanom bodovom grafe.


