
Existuje mnoho případů použití, které vyžadují nějaký druh porovnání. Můžete být požádáni porovnat obchodníky, oddělení, země, technologie nebo dokonce druhy květin. Dnes budeme pracovat se známým datovým souborem Iris. Na jednu stranu se cítím trochu provinile kvůli nedostatku kreativity při výběru datového souboru, na druhou stranu je tento dataset snadno ke stažení, snadno pochopitelný a umožňuje vytvořit pěkně vypadající hustotní graf. Data si stáhněte zde. CSV obsahuje 50 vzorků 3 různých druhů kosatců a atributy: délku kališních lístků (sepal length), šířku kališních lístků (sepal width), délku okvětních lístků (petal length) a šířku okvětních lístků (petal width) v cm. Nahrajte data do Qlik Sense tak, aby byl v datovém modelu pouze 1 tabulka, nejsou potřeba žádné transformace. Tabulku pojmenujte IrisData.
Ukaž mi čísla
Budeme porovnávat délku kališních lístků u 3 různých druhů. První, co mě napadne, je spočítat průměr pro každý typ kosatce. Někdo by mohl namítnout, že medián je lepší volba — a měl by pravdu. Pokud chceme zjistit střed dat, medián je obvykle lepší volba. Udělejme obojí: 
Teď víme, že nejdelší kališní lístky má versicolor, ale co když se délky v rámci jednoho druhu výrazně liší? Čím větší je rozptyl, tím méně významné jsou rozdíly v průměrech. Velmi známou mírou variability je směrodatná odchylka:
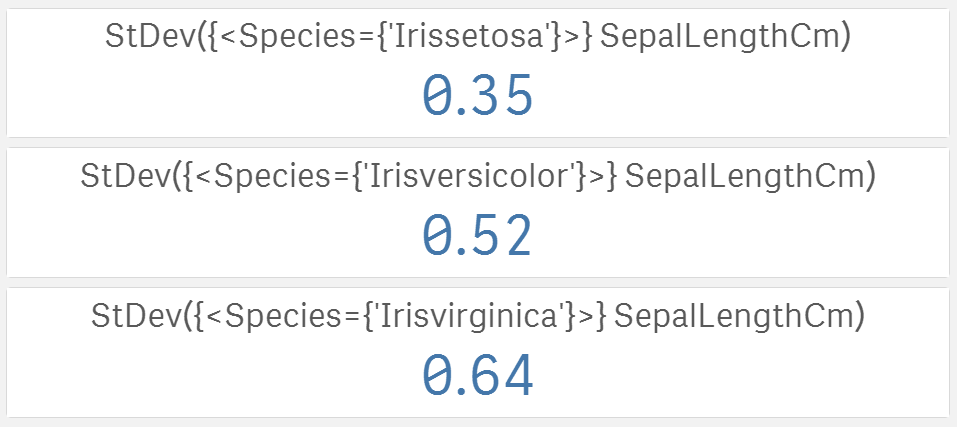
Nyní víme, že setosa má mnohem menší rozptyl než virginica. Poslední chybějící informací je tvar dat.
Vizualizace rozdílů
Jsou délky vychýlené (šikmé), nebo symetrické? Možná je některé rozdělení „špičatější“ než ostatní (mohli bychom také spočítat špičatost — kurtózu). Histogram by nám to mohl ukázat, ale nejsem velkým fanouškem histogramu v Qlik Sense. Nechápejte mě špatně — Qlik je skvělý BI nástroj, ale jednoduše není navržen jako statistický nástroj. Nejvíce mi chybí nastavení min/max hodnot na ose x (není dostupné ve verzi November 2019 a starších), které by bylo velmi užitečné pro porovnání tvaru, středů, šikmosti a kurtózy. Ale pracujme s tím, co máme:

Nevím jak vy, ale tyto histogramy nám poskytly jen velmi málo informací vzhledem k potenciálu tohoto grafu. Ano, jsou zde rozdíly v tvarech, ale jak velké ty rozdíly jsou? Kvůli chybějícímu nastavení min/max na ose x nám unikají informace o rozdílech ve středech dat i v rozptylu. Například už víme ze směrodatné odchylky, že setosa má nejmenší rozptyl — ale vidíte to tady? Pokud se nepodíváte na hodnoty na ose x, můžete snadno dojít k závěru, že rozptyl všech tří je stejný — což by bylo daleko od pravdy. Budeme muset jít trochu hlouběji.
V Qlik Sense existují 2 pěkné vizualizace, které ukazují, kde se data nacházejí a jak velký je rozptyl — v jednom obrázku: distribučný graf vlevo a box plot vpravo. Pokud jste mistři box plotu, můžete v něm trochu vidět i tvar.

To mi ale nestačí. Musí existovat lepší způsob, jak to všechno vidět pěkně v jednom jednoduchém obrázku. Pomůžeme si pomocí R a vytvoříme hustotní graf v Qlik Sense.
Použití R pro získání dat hustotního grafu
Použijeme R pro výpočet hodnot hustoty. Pokud se chcete dozvědět více o funkci hustoty a jejím fungování, podívejte se zde. Existují 2 způsoby, jak propojit R a Qlik Sense. Buď je ponechat odděleně a načíst výsledky z R do Qlik Sense jako jakýkoli jiný zdroj dat, nebo použít SSE R-plugin pro odeslání dat, spuštění R skriptu a přijetí výsledků přímo v Qlik Sense bez nutnosti ukládání externě. Následující řádky lze použít, pokud máte Qlik Sense integrován s R pomocí pluginu. S trochou znalostí R lze skript snadno upravit i pro běh mimo Qlik Sense.
IrisDataDensity: Load * Extension R.ScriptEval( '# install.packages(tidyverse, repos="http://cran.us.r-project.org"); //ponechte # pokud již máte balíček nainstalovaný # install.packages(magrittr, repos="http://cran.us.r-project.org"); //ponechte # pokud již máte balíček nainstalovaný library(tidyverse); library(magrittr); data <- as.data.frame.list(q); data %<>% pivot_wider(names_from = "Species", values_from = "SepalLengthCm") %>% apply(2, density, na.rm=TRUE) %>% unlist(recursive=FALSE);
result <- as.data.frame( data[endsWith(names(data), ".x")|endsWith(names(data), ".y")]);
result %<>% mutate(DensID = row_number()) %>% select(DensID, everything()) %>% select(-c("Id.x", "Id.y")) %>% pivot_longer(cols = -"DensID") %>% separate(col = name, into = c("Iris", "Species", "Coordinate")) %>% mutate(Species = paste(Iris, Species, sep = "-")) %>% select(-Iris) %>% pivot_wider(names_from = "Coordinate", values_from = "value");',
IrisData{Id, SepalLengthCm, Species});
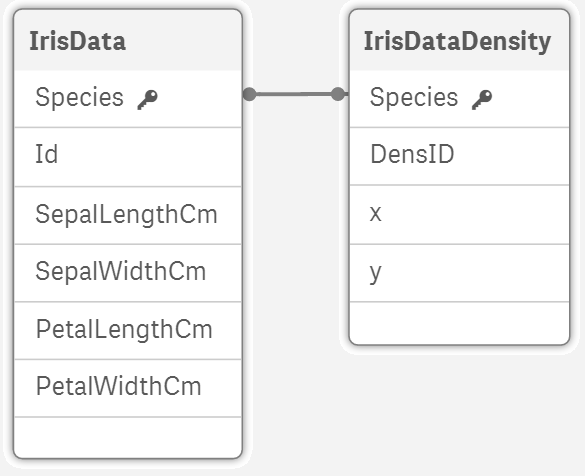
Skript přidá novou tabulku do našeho datového modelu:
Vytvoření hustotního grafu
Jako základ použijeme standardní čárový graf. Nastavte následující:
- x jako dimenzi skupiny
- Species jako dimenzi čáry
- y jako míru
- přepněte čárový graf na plošný graf v sekci prezentace
- v nastavení osy x zaškrtněte možnost Use continuous scale
- nastavte popisky a název
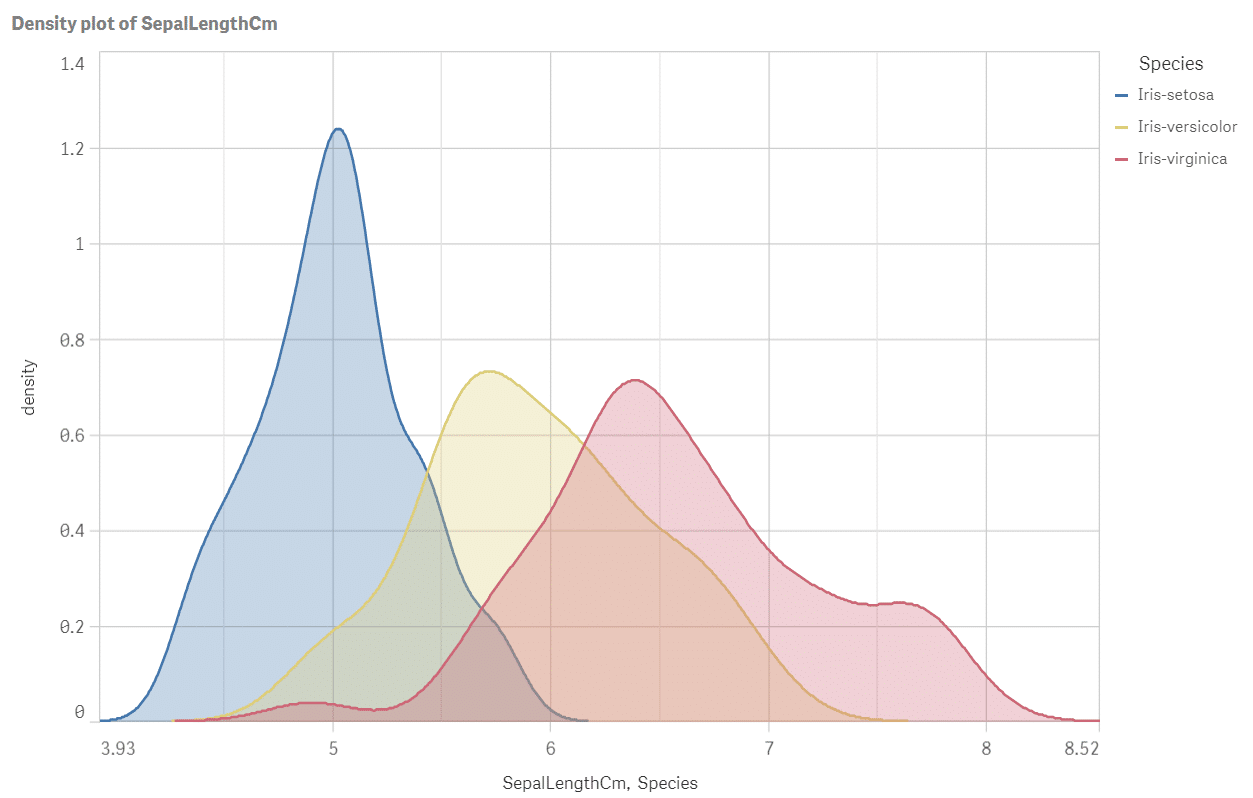
Perfektní! Máme všechny odpovědi v jednom obrázku: jak se jednotlivé druhy liší z hlediska polohy, rozptylu a tvaru dat délky kališních lístků? Nejdelší kališní lístky jsou typické pro virginica a nejmenší pro setosa. Podívejte se na šířku grafu: rozptyl virginica je přibližně dvakrát větší než u setosa. Versicolor se zdá být mírně vychýlený a rozdělení setosa je více „špičaté“. Spusťte skript i pro další atributy kosatců, nebo ještě lépe: optimalizujte ho a upravte tak, aby počítal hustotu pro všechny míry SepalLengthCM, SepalWidthCm, PetalLengthCm a PetalWidthCm najednou.
Podívejte se také na poslední článek ze série Creative visualisations in Qlik Sense o animovaném scatter plotu.


